

| March 26, 2024
Идея этого поста родилась в качестве ответа на обсуждение мониторинга Spring Boot приложений, развёрнутых в Kubernetes кластере, на одном из курсов по архитектуре, который я проходил.
Так получилось, что кроме меня, на том занятии не было людей, работваших с указанным стеком, поэтому, как носитель экспертизы в этом вопросе, я решил помочь коллегам-студентам обрести знания и понимание в этом вопросе.

Эта статья не является туториалом. Здесь Вы не найдёте инструкций, как что делать по шагам. Однако, цель этой статьи именно пролить свет на то, как работает связка Spring Boot + Kubernetes + Prometheus для организации мониторинга работы прииложений. Если, в процессе чтения, появится желание углубиться в определённую тему - для Вас будут доступны полезные ссылки.
Использование Prometheus в связке с приложениями Spring Boot, развёрнутыми в Kubernetes кластере - довольно распространённая вещь. Когда разработчик приходит на такой проект, зачастую “всё само работает”, и не требуется никаких вмешательств с его стороны. А если требуется - есть бригада DevOps’еров, которые готовы придти на помощь в этом вопросе. Именно это и порождает тотальное непонимание в вопросе - а как вся эта связка вообще работает.
Так как это всё вообще работает? Давайте разбираться! И начнём, с самого основного понятия.
Что такое метрика?
Метрика - это числовой, измеряемый параметр. Пример:
- количество запросов
- время обработки запроса
Как метрики попадают в Prometheus?
Есть две модели доставки метрик в Prometheus:
- push - когда инстанс сервиса сам выгружает метрики в Prometheus с какой-то периодичностью
- pull - когда Prometheus сам загружает метрики из инстанса сервиса с какой-то периодичностью
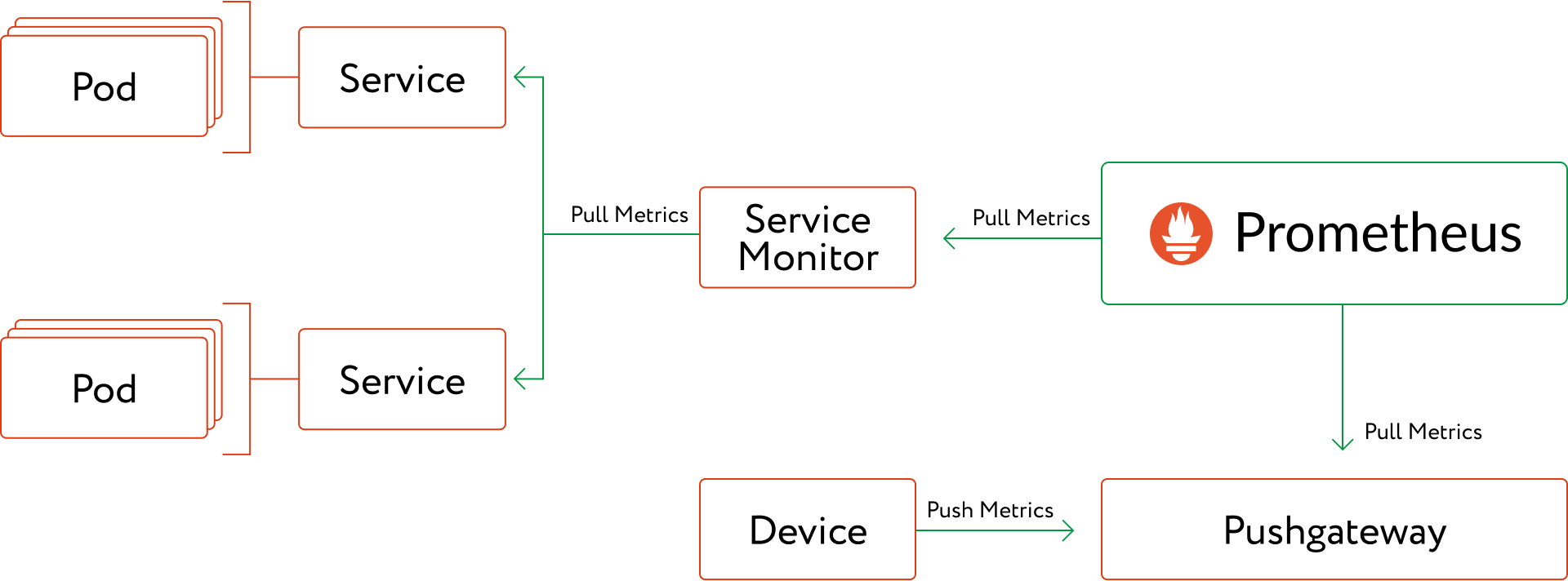
Push - подход
В случае использования push-подхода, как инстанс сервиса узнаёт куда конкретно выгружать метрики?
В конфигурацию самого сервиса добавляется адрес Prometheus Pushgateway. Pushgateway - нужен для приёма метрик от сервисов, когда инициатором отправки метрик в Prometheus является сам сервис.
Соответсвенно, когда у нас выкатывается новая версия, разворачиваются новые поды - они используют ранее добавленную конфигурацию и выгружают свои метрики по тому-же адресу Pushgateway’я.
Больше об этом тут: When to use the Pushgateway
Pull - подход
В случае использования pull-подхода - всё становится интереснее.
Pull-модель в Prometheus ожидает, что инициатором выгрузки метрик в Prometheus является сам Prometheus. То есть, он должен пройтись по инстансам сервиса, развёрнутого в Kubernetes и получить с них метрики. Как в этом случае Prometheus узнаёт адреса инстансов, по которым нужно сходить за метриками?
Для этого есть кастомные объекты Kubernetes (например: ServiceMontior), которые конфигурируются с помощью label’ов Kubernetes. То есть, буквально «все поды с меткой observable имеют энд поинт /actuator/prometheus». И затем, эта информация передаётся в Prometheus как список адресов сервисов Kubernetes, у которых есть этот label и Prometheus знает куда ходить за метриками. За эти возможности отвечает Prometheus Operator.
Соответсвенно, когда у нас выкатывается новая версия, разворачиваются новые поды - ServiceMonitor в составе Prometheus Operator’а отслеживает эту информацию и обновляет конфигурацию Prometheus, чтобы он мог ходить по свежим адресам.
Больше об этом тут: Using Service Monitors :: Observability for Kubernetes и тут Устройство и механизм работы Prometheus Operator в Kubernetes
В каком виде метрики отдаются сервисом?
На стороне Java приложения на Spring Boot может быть настроен actuator.
Таким образом на выделенном URL (например, /actuator/prometheus), будет отдаваться ответ с метриками, в формате пригодном для Prometheus.
Как конкретно выглядят метрики для Prometheus, отдаваемые через Actuator в Spring Boot приложении? Вот пример из интернета:
# TYPE jvm_memory_committed_bytes gauge
jvm_memory_committed_bytes{area="heap",id="G1 Survivor Space",} 9437184.0
jvm_memory_committed_bytes{area="heap",id="G1 Old Gen",} 9.961472E7
jvm_memory_committed_bytes{area="nonheap",id="Metaspace",} 4.2254336E7
jvm_memory_committed_bytes{area="nonheap",id="CodeHeap 'non-nmethods'",} 2555904.0
# TYPE jvm_gc_live_data_size_bytes gauge
jvm_gc_live_data_size_bytes 0.0
# HELP tomcat_sessions_active_max_sessions
# TYPE tomcat_sessions_active_max_sessions gauge
tomcat_sessions_active_max_sessions 0.0
# HELP jvm_threads_live_threads The current number of live threads including both daemon and non-daemon threads
# TYPE jvm_threads_live_threads gauge
jvm_threads_live_threads 27.0
где, например, vm_threads_live_threads - название метрики, 27.0 - её значение в данный момент.
Метрики в Prometheus
Теперь, когда мы знаем, как выглядят метрики и как они попадают в Prometheus, стоит задуматься вот о чём:
- Pod’ов (точнее, инстансов нашего сервиса) может быть больше одного
- Сам Prometheus ничего не знает об источниках метрик
Поэтому метрика выше - vm_threads_live_threads 27.0 - скорее безсмысленна.
В случае с одним инстансом сервиса - у нас будет сразу же ясно на каком инстансе у нас количество потоков равно 27.
В случае же, когда у нас, допустим, три инстанса выгружают метрики в Prometheus, список метрик будет следующим:
vm_threads_live_threads 27.0
vm_threads_live_threads 23.0
vm_threads_live_threads 1.0
При попытке запросить эти данные в Prometheus, мы получим значение метрики 51, то бишь - сумму.
Почему так? Потому что, смотрим на тезисы выше, сам Prometheus ничего не знает об источниках. Для него центральным понятием является метрика. Вот метрику он и показывает.
Чтобы наполнить использование Prometheus смыслом - используются label’ы (иногда их называют tag’ами). Что это такое? Это способ разметить конкретное значение метрики, или добавить контекстной информации для неё. Например, мы можем каждой метрике навесить лэйбл pod_name, и тогда в Prometheus, мы явно будем знать значение метрики для конкретного Pod’а. В примере ответа actuator’а можно найти использование лэйблов:
jvm_memory_committed_bytes{area="heap",id="G1 Old Gen",} 9.961472E7
{area="heap",id="G1 Old Gen",} - вот эта штука и есть перечень лэйблов: area, id.
Теперь, допустим у нас есть три пода, каждый из них навешивает на каждую (!) метрику собранную на нём лэйбл pod_name. Тогда при попытке получить значение
vm_threads_live_threads мы получим то же самое - 51, но при попытке сделать vm_threads_live_threads{pod_name="[имя пода]"} мы получим конкретное значение метрики на конкретном поде.
Больше о работе с лэйблами можно почитать здесь: Metric and label naming
Добавлю, что в реальной разработке на метрики навешивается довольно широкий перечень лэйблов. Всё это нужно для того, чтобы можно было анализировать собранные метрики по любым разрезам, которые нам требуются. Довольно стандартная штука проставлять метркам лэйблы:
app/service_name= название нашего сервисаpod_name= название подаapp_version= версия сервисаip-адрес= тоже видел довольно часто
Что происходит, когда накатывается новая версия приложения?
Kubernetes гасит старые Pod’ы, стартует новые. Старые перестают отдавать метрики со своими лэйблами, новые начинают отдавать метрики с новыми лэйблами. Какие-то лэйблы НЕ меняют значения (например service_name), какие-то меняют (например app_version или pod_name). И таким образом, визуализируя метрику из Prometheus:
vm_threads_live_threads{service_name="my_svc"} мы увидем как менялись значения со временем для нашего сервиса, НЕ зависимо от того, какие Pod’ы в какой-момент времени эти метрики поставляли. А визуализируя:
vm_threads_live_threads{service_name="my_svc", pod_name="qwerty} мы увидим только изменение этой метрики для нашего сервиса на конкретном поде, когда он был активен.
Выводы
Надеюсь, прочитав эту статью, Вы поймёте путь, который проходит метрика от приложения, развёрнутого в Kubernetes до Prometheus, а в качестве основной идеи запомните, что Prometheus - универсальный инструмент для решения задач observability.
В нём можно мониторить как показания «средние по больнице», так и опускаться до индивидуальных элементов вашей системы.
Список материалов
- [1] Когда использовать Pushgateway? - раздел документации Prometheus о Pushgateway
- [2] Using Service Monitors :: Observability for Kubernetes - инструкция по использованию ServiceMontitor’ов из Prometheus Operator
- [3] Устройство и механизм работы Prometheus Operator в Kubernetes - статья на habr’е о работе Prometheus Operator
- [4] Spring Boot Actuator - документация Spring Boot Actuator
- [5] Metric and label naming - раздел документации Prometheus о “Метриках и Лейблах”