

| March 19, 2024
Что такое Risk Storming?
Это метод, позволяющий легко и быстро, коллективно и визуально идентифицировать риски в системе. Метод подразумевает участие нескольких людей. Для более широкого взгляда на рассматриваемую систему, полный состав участников может включать в себя людей из разных направлений и с разными навыками.
Метод
Сам метод состоит из нескольких последовательно выполняемых шагов. Разберём каждый их них.
Шаг 1: Нарисовать диаграммы архитектуры
Поскольку метод подразумевает поиск рисков в готовой или строящейся системе, нам необходимо эту самую систему каким-то образом видеть.
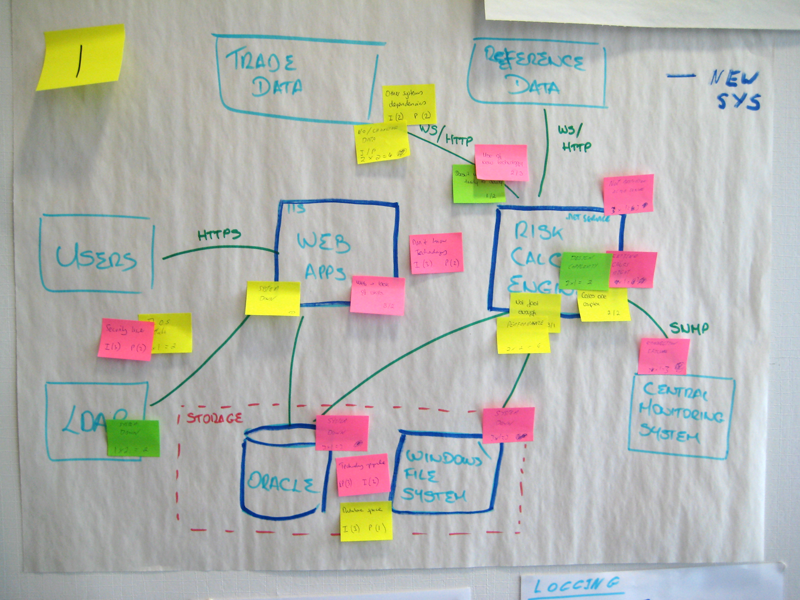
Диаграммы архитектуры в этом плане - прекрасное подспорье. Они проиллюстрируют основные компоненты системы и их взаимосвязи.
Шаг 2. Индивидуальный поиск рисков
На данном шаге, каждый из участников выписывает абсолютно любые риски и проблемы, пришедшие ему в голову, на стикеры.
Этот шаг проводится в абсолютной тишине и должен быть ограничен по времени. Например, 5-10 минут может быть вполне достаточно.
Примерами рисков могут быть абсолютно любые предположения о неработоспособности чего-либо. Например:
- Формат данных в сторонней системе изменился
- Внешние сервисы недоступны
- Неконсистентость данных
Шаг 3. Делимся предположениями
На данном шаге, все участники сессии размещают свои стикеры на диаграммах архитектуры, на основе которых производился поиск рисков.
Стикеры размещаются близко к той части диаграммы, к которой относятся описанные риски.
Если несколько участников сессии описали схожие риски, стикеры этих рисков располагаются вместе.

Шаг 4. Приоритизация
И на заключительном шаге, каждый из найденных рисков, рассматривается и обсуждается коллективно.
Задача этого шага определить насколько высокий приоритет имеет найденная потенциальная проблема.
Вариантов оценить приоритет несколько. Я опишу их два:
- Planning Poker (PlanningPoker.com - Estimates Made Easy. Sprints Made Simple.) - это когда участники оценивают риски, используя карты с цифрами и коллективно обсуждая. В конце концов, переговоры должны придти к общему пониманию.
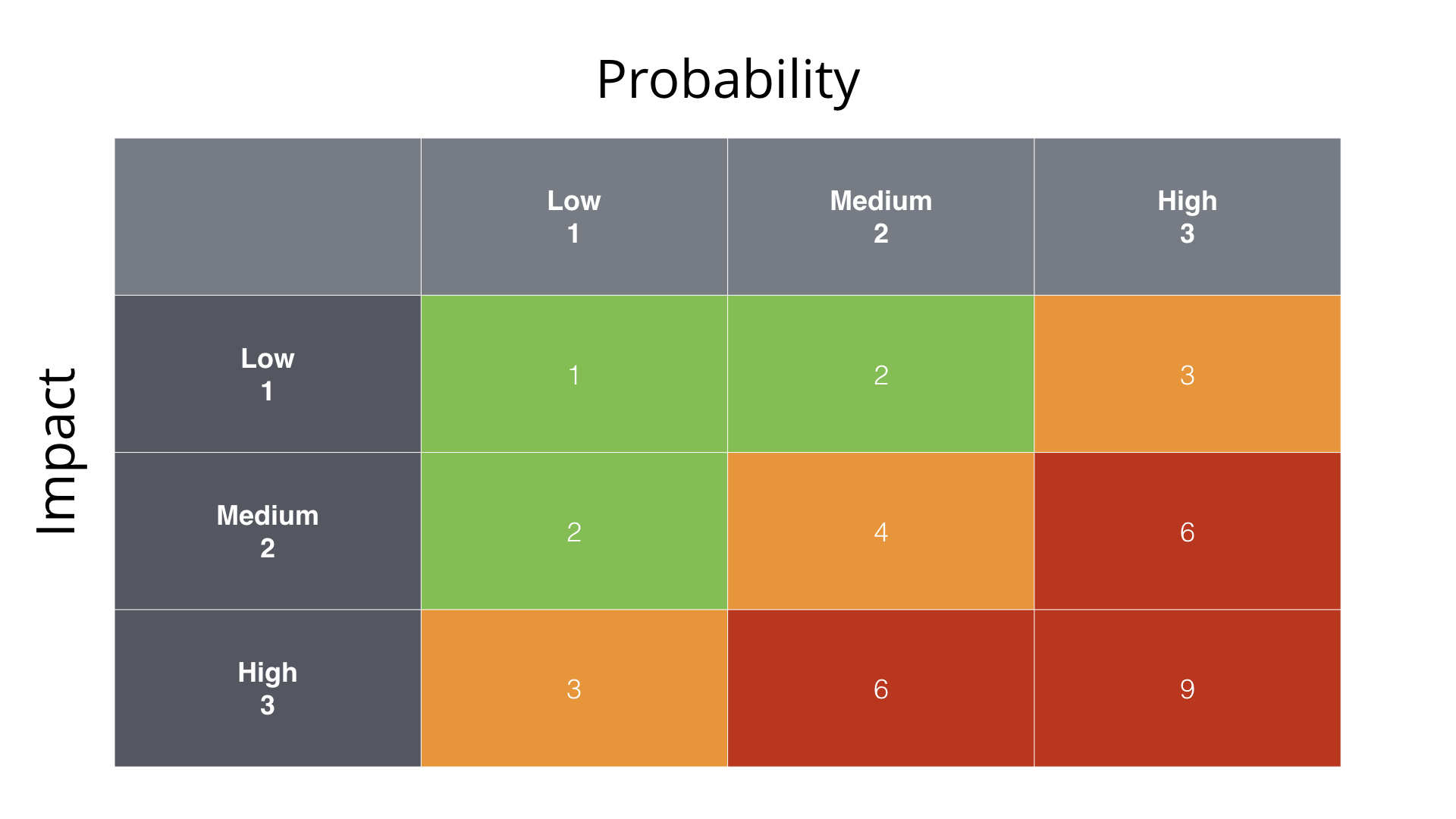
- Используя специальную матрицу, на которой на одной оси располагается Вероятность возникновения (Probability) проблемы, а на другой - её Влияние (Impact).
Пример
Для того, чтобы посмотреть на метод в действии, нам понадобится архитектурная схема системы. Поскольку подход абсолютно универсальный - я взял произвольную схему из Интернета: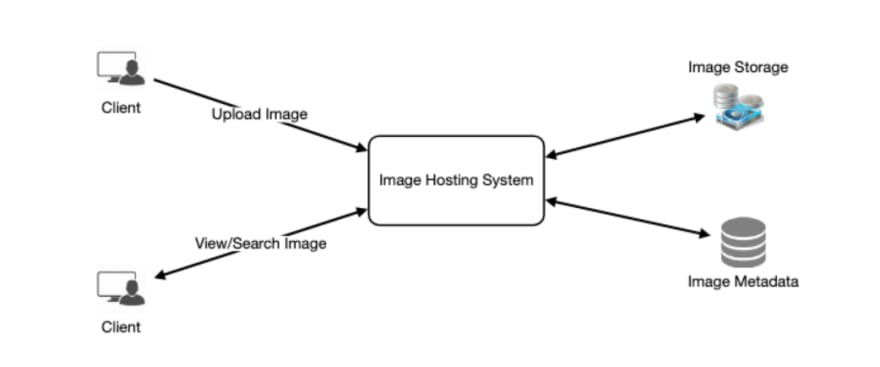
Теперь, когда у нас есть схема архитектуры мы можем приступать.
Следующим шагом будет попытка каждого участника идентифицировать риски, возможные в абсолютно любой части системы. Риски описываются на стикерах и затем, стикеры, располагаются на той части схемы, к которой риск, описанный на нём, относится.
У меня получилось следующее: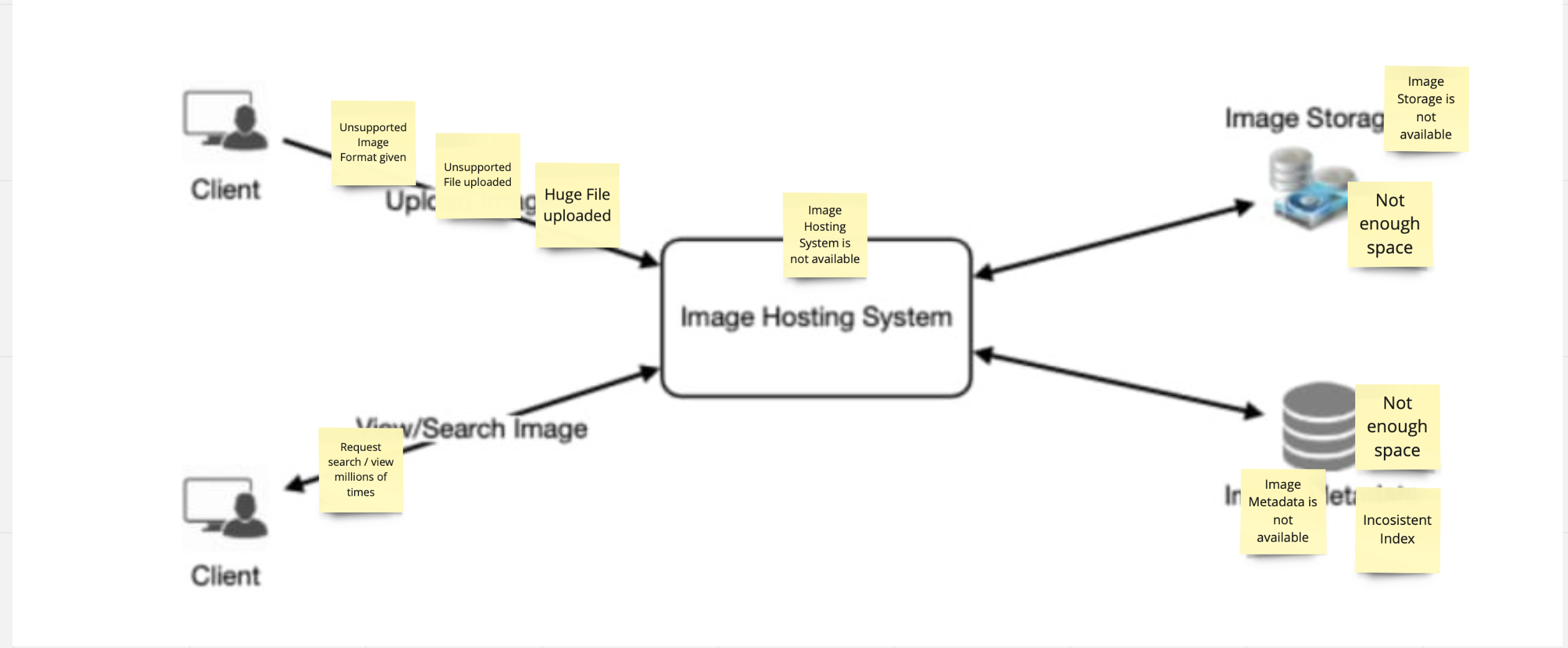
Напомню, что цель данного метода не вычислить каждый возможный потенциальный риск. Естественно, должны быть пределы разумного. «Нападение акул на сотрудников дата центра» - хорошая идея, но это гарантированно не произойдёт (если только дата центр не располагается на дне океана).
Следующим шагом будет коллективная оценка каждого найденного риска, с помощью принятого в команде метода оценки. Для примера я воспользуюсь методом с матрицей. Давайте попробуем оценить приоритет риска с загрузкой в наш сервис гигантского файла (нужно прояснить, под гигантским файлом я имею ввиду любой контент, размер которого выходит за пределы разумного и принятого для данной системы).
Загрузка гигантского файла может заставить нашу систему расходовать большое количество ресурсов на его обработку и хранение. Более того, предположим что наш Image Storage, это S3 сервис от AWS, а это значит что хранение гигантских объёмов данных будет стоить нам больших денег. Поэтому я полагаю, что Вероятность, что кто-то попробует это провернуть не нулевая, так что Medium, а Влияние на работоспособность системы и её обслуживание велико, то есть High. Оценив риск таким образом, я поместил его в соответствующую строку и колонку.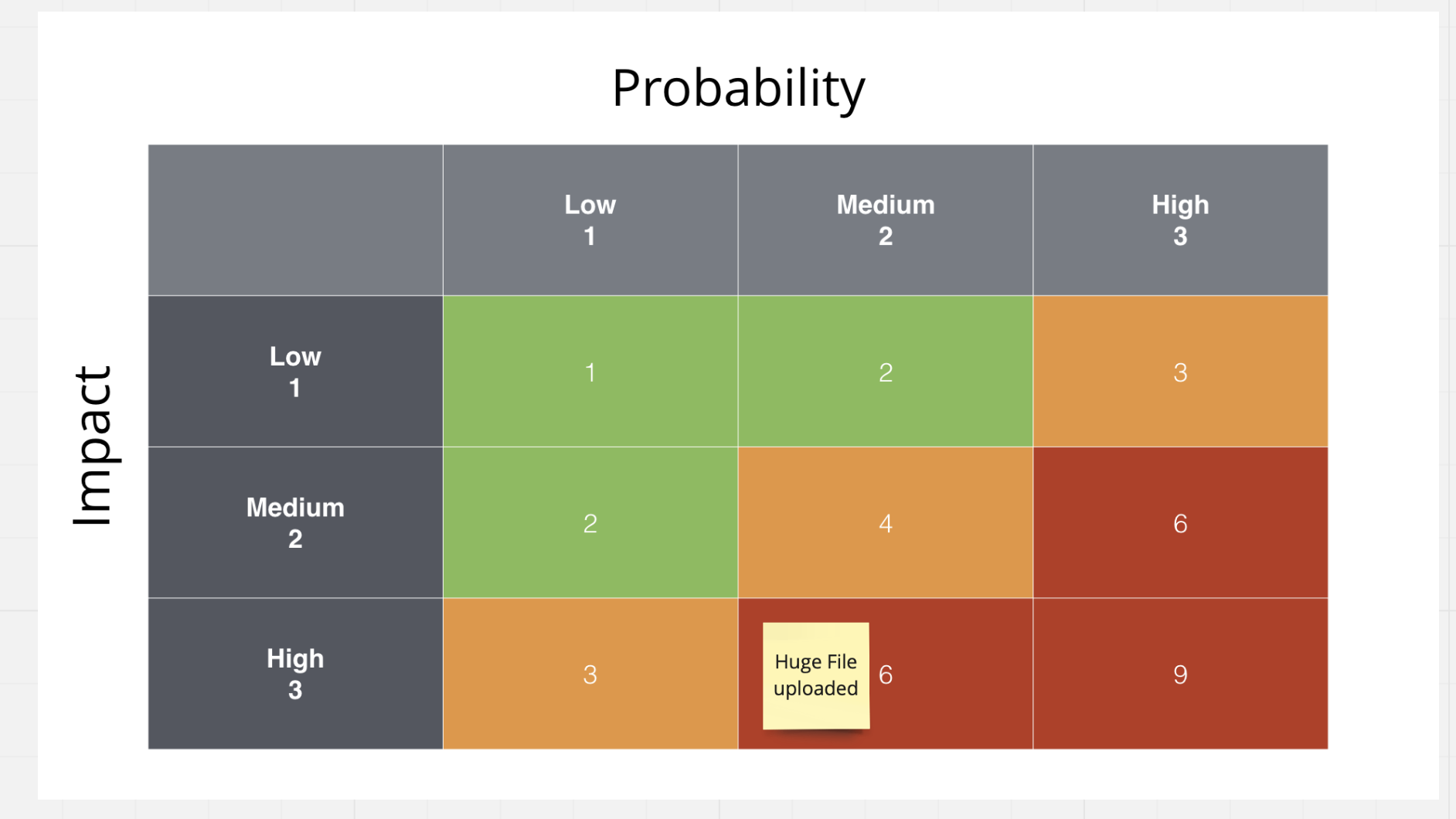
Аналогично, нужно поступить и с каждым из оставшихся рисков. В итоге, мы получим примерно следующую картину: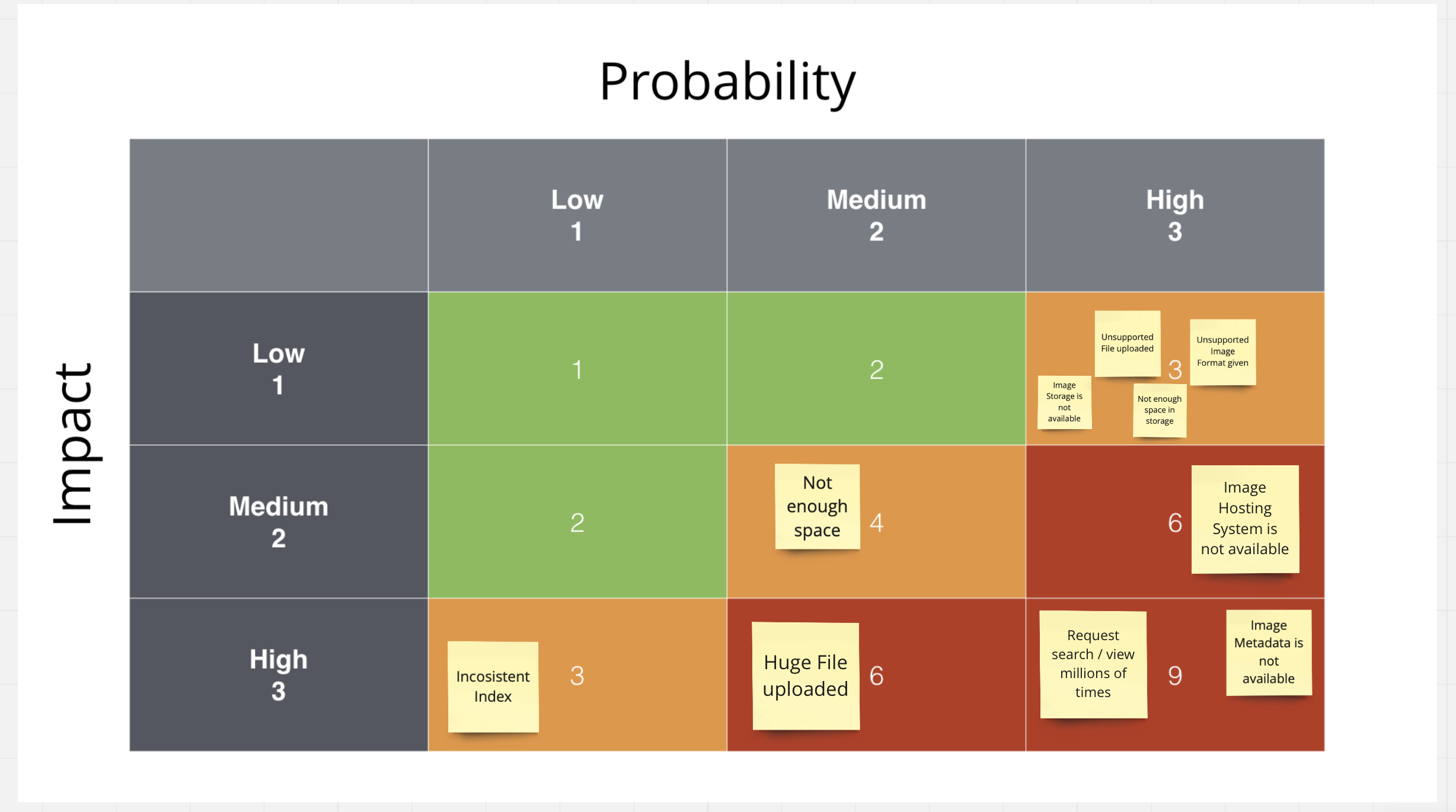
Итак, мы получили оценки для каждого из рисков. С матрицей уже сейчас можно сделать выводы о том, какие из рисков нужно постараться обработать быстрее остальных. Например, неограниченное количество запросов к сервису может привести к полному отказу работоспособности сервиса из-за DDOS атаки.
Список рисков с их оценкой в дальнейшем послужит отличной вводной информацией для формирования технического бэклога команды, обслуживающей сервис.
Дополнительные материалы
- [1] Risk-storming - веб-сайт методологии
- [2] https://leanpub.com/software-architecture-for-developers - книга автора методологии. В самой книге, методологии посвящена небольшая глава.